Hace apenas unos años, la idea de que una máquina pudiera aprobar un examen médico parecía ciencia ficción. Hoy, la realidad es otra.
En NEJM AI, el modelo GPT-4 fue puesto a prueba con casos clínicos complejos —de esos que hacen sudar incluso a los residentes más brillantes— y logró algo sorprendente: diagnosticó correctamente el 57 % de los casos, superando a los médicos humanos que resolvieron las mismas viñetas, que acertaron en torno al 36 %.
Sí, una IA logró razonar a partir de síntomas, laboratorios e imágenes y proponer diagnósticos plausibles. En otras palabras: un modelo de texto demostró que podía pensar como un clínico.
Y los avances no se detienen ahí. Versiones más recientes —como GPT-5 o los equivalentes multimodales de Google, OpenAI y Anthropic— ya obtienen puntajes extraordinarios en los exámenes médicos estandarizados, como el USMLE. Algunos alcanzan entre 85 % y 90 % de aciertos, muy por encima del umbral de aprobación. La IA, al menos en papel, ya puede “graduarse de medicina”.
Mientras tanto, los modelos especializados de Google en radiología lograron superar a radiólogos humanos en la detección de cáncer de mama, reduciendo falsos positivos y falsos negativos. En esos escenarios controlados, el desempeño es espectacular.
Y ahí surge la pregunta inevitable:
Si ya diagnostica, ya interpreta imágenes y ya pasa los exámenes… ¿qué queda para los médicos?
La respuesta corta: mucho más de lo que parece. Porque no todo lo que brilla en un benchmark reluce en el mundo real.
Los modelos de lenguaje, como GPT-4 o Gemini, han aprendido a resolver preguntas estructuradas, del tipo selección múltiple. Pero hay un detalle que pocos mencionan: cuando los investigadores modificaron una sola opción y agregaron “ninguna de las anteriores”, el rendimiento se desplomó.
En el estudio It is Too Many Options: Pitfalls of Multiple-Choice Questions in Generative AI and Medical Education, los modelos perdieron casi 40 puntos porcentuales cuando tuvieron que responder sin opciones dadas. En otras palabras, son excelentes eligiendo entre alternativas, pero mucho menos hábiles creando una respuesta desde cero.
Eso no es pensamiento clínico. Eso es predicción estadística. Y ahí está la diferencia entre un modelo y un médico. El médico no busca la opción correcta: busca la verdad que aún no tiene nombre.
Durante años se dijo que los radiólogos serían los primeros en desaparecer. Que los algoritmos leerían todas las placas y que las máquinas firmarían los informes. Pero los hechos cuentan otra historia.
Un artículo reciente, “AI Isn’t Replacing Radiologists”, lo explica con claridad: la IA puede detectar patrones, pero no entiende el contexto clínico. Una sombra en una tomografía puede ser neumonía, cáncer o simplemente un artefacto. Solo el médico, con toda la historia del paciente en mente, puede decidir qué significa.
Y los datos lo confirman. En Radiology’s Last Exam (RadLE), publicado en 2025 por Suvrankar Datta y colegas, se evaluó a los modelos más avanzados —GPT-5, o3, Gemini 2.5 Pro, Grok-4 y Claude Opus 4.1— frente a radiólogos certificados en 50 casos de diagnóstico visual complejo. El resultado fue contundente:
- Radiólogos: 83 % de aciertos.
- Mejor modelo (GPT-5): apenas 30 %.
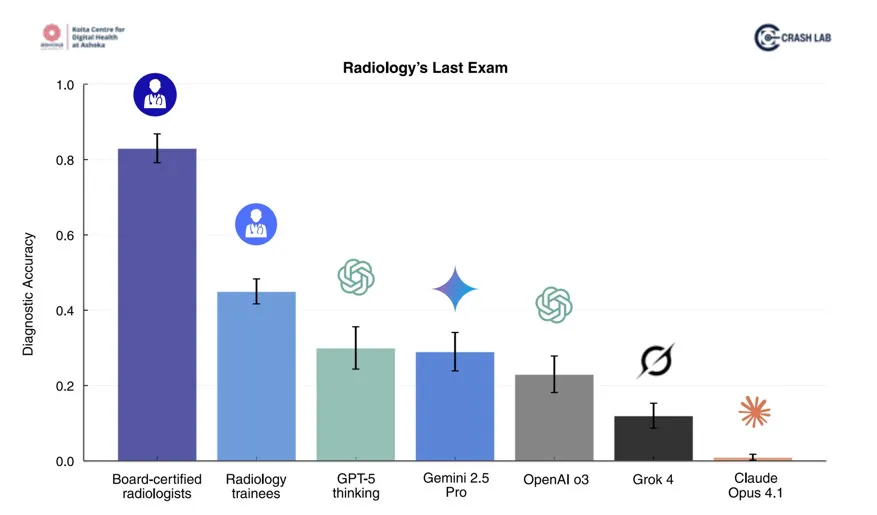
Además, los investigadores clasificaron los errores de la IA en categorías fascinantes: desde “confusión anatómica” hasta “falta de foco clínico”. Incluso cuando el modelo tenía buena intuición visual, le faltaba la historia detrás de la imagen.
Los llamados benchmarks son como los Juegos Olímpicos de la IA: pruebas estandarizadas donde se compara el desempeño de diferentes modelos. En salud, estos incluyen desde bancos tipo USMLE hasta desafíos radiológicos o clínicos complejos.
Pero hay una trampa: los benchmarks simplifican la realidad. El mundo no te da cuatro opciones; te da miles de variables, emociones y seres humanos que cambian de opinión. En ese entorno, un modelo puede tener un 90 % de precisión y aun así fallar catastróficamente en un solo paciente. La medicina no perdona ese 10 %.
Por eso, los investigadores ahora diseñan nuevos benchmarks que no miden solo aciertos, sino razonamiento, reproducibilidad y ética. Buscan evaluar no qué tan bien responde un modelo, sino cómo llega a esa respuesta.
Hay algo que la IA aún no puede imitar: la experiencia y la auténtica empatía. La capacidad de un médico para leer entre líneas, sentir la urgencia en la voz del paciente o notar el silencio en una consulta no tiene equivalente digital.
Los modelos son herramientas poderosas, sí. Pero son herramientas. No sienten responsabilidad moral, no construyen confianza, no cargan con la mirada del familiar que pregunta “¿va a mejorar?”.
Y además, su desempeño cambia con cada actualización, cada fine-tuning, cada cambio en el prompt. No son reproducibles con la estabilidad que exige la medicina.
La medicina es demasiado compleja, demasiado humana, demasiado imperfecta para reducirla a un algoritmo.
Lo verdaderamente transformador no será reemplazar médicos, sino potenciarlos.
Imagina una medicina donde el clínico se enfoca en la relación, en el criterio, en la decisión difícil; y la IA, mientras tanto, procesa miles de variables, compara patrones globales y sugiere opciones que de otro modo nadie habría visto.
Ese futuro no es amenaza, es oportunidad. Una oportunidad para volver a lo esencial: la medicina como conversación, no como cálculo.
Y ahí, la inteligencia artificial puede ser una gran aliada. No para sustituirnos, sino para devolvernos tiempo, foco y humanidad.
Los modelos mejoran, los benchmarks evolucionan y los titulares seguirán gritando que la IA ya superó a los médicos. Pero al final del día, cuando un paciente te mira a los ojos y pregunta: “Doctor, ¿usted qué haría si fuera su madre?”, ningún algoritmo tiene aún esa respuesta.
 | Fernando Bonilla Sinibaldi, MD, MSc, MBA Consultor y Divulgador Salud Digital e Inteligencia Artificial en Salud Health Transformers 360 https://substack.com/@iaensalud |